Macroeconomic forecasting with Gaussian processes
정확한 거시경제 예측은 사업 결정, 금융 거래, 그리고 정치인과 경제학자들에 의한 정책 결정의 근거로서 필수적입니다. 전통적으로 시계열 데이터에 대한 선형 회귀 또는 밀접하게 관련된 방법을 통해 수행되었습니다.
본 포스팅에서는 인기 있는 비선형적 방법인 가우스 프로세스 회귀 분석을 사용하여 여러 국가의 GDP를 예측하여 전통적인 기법보다 더 나은 결과를 얻을 수 있는지 여부를 확인하고자 합니다.
가장 중요한 거시경제변수는 아마도 국내총생산(GDP)일 것입니다. 그것은 한 지역에서 판매되는 모든 상품과 서비스의 가치를 측정하기 때문입니다. 따라서 우리는 GDP 예측에 초점을 맞출 것입니다.
전체적으로는 다음과 같이 구성됩니다.
1. 먼저 데이터를 로드하고 변환한 다음,
2. simple baseline method 및 multivariate time-series regression을 평가하고
3. 마지막으로 가우스 프로세스(GP) 회귀 분석과 비교합니다.
Environment
우리는 pandas, statsmodels, scikit-learn 패키지를 사용할 것입니다.
콘솔이나 터미널에 아래와 같은 명령어로 설치합니다.
> pip3 install pandas
> pip3 install statsmodels
> pip3 install sklearn
Configuration
첫 째로, 우리는 configuration을 특정할 것입니다. 만약 다른 나라, 기간, indicators가 필요하다면 코드를 바꾸시면 됩니다.
Input:
# out-of-sample로 사용할 년도의 수
#(실제 GDP와 비교하여 매년 국가별로 하나의 예측을 할 것입니다)
nyears = 10
# GP regression에 사용할 lag의 수
lags = 5
# Indicator labels과 the World Bank API에서의 이름
indicators = {"gdp" : "NY.GDP.MKTP.CD",
"population" : "SP.POP.TOTL",
"inflation" : "FP.CPI.TOTL.ZG"}
nindicators = len(indicators)
# 예측하기 위한 변수, indicator labels 중에 하나여야 함
target_variable = "gdp"
# Countries to include in the data, specified as ISO country codes
countries = ['au','ca','de','es','fr','gb','jp','us']
ncountries = len(countries)
# 데이터 셋의 시작 연도와 마지막 연도
start_year = 1976
end_year = 2018
Data
Loading
먼저 우리는 몇몇의 거시경제 지표들을 the World Bank HTTP API를 통하여 다운받을 것입니다. 여기서 Python의 requests 패키지를 사용하게 됩니다.
먼저 우리가 위에 configuration에서 설정했던 각각 다른 나라들, indicator로 채워질 template url을 특정합니다. 우리가 URL에 request할 때, 그 데이터들은 json 형식으로 fetched 될 것입니다. 우리는 그것들을 pandas dataframe에 넣을 것입니다.
import requests
import pandas as pd
template_url = "http://api.worldbank.org/v2/countries/{0}/indi"
template_url += "cators/{1}?date={2}:{3}&format=json&per_page=999"
# Countries는 세미 콜론으로 분리됩니다.
country_str = ';'.join(countries)
raw_data = pd.DataFrame()
for label, indicator in indicators.items():
# template URL을 채웁니다.
url = template_url.format(country_str, indicator, start_year, end_year)
# 데이터를 request하고
json_data = requests.get(url)
# JSON String을 python object로 변경합니다.
json_data = json_data.json()
# 반환되는 데이터는 리스트이며, 첫 번째 element는 meta데이터,
# 두 번째 element가 실제 데이터입니다.
json_data = json_data[1]
# 모든 데이터 포인트를 loop하며 value들을 dataframe으로 확장합니다.
for data_point in json_data:
country = data_point['country']['id']
# 각각 나라, indicator로 variable을 만듬
item = country + '_' + label
year = data_point['date']
value = data_point['value']
# DataFrame으로 Append
new_row = pd.DataFrame([[item, year, value]],
columns=['item', 'year', 'value'])
raw_data = raw_data.append(new_row)
# 데이터를 피벗하여 columns을 따라 특정 연도를 얻고, rows를 따라 variable을 얻습니다.
raw_data = raw_data.pivot(index='year', columns='item', values='value')
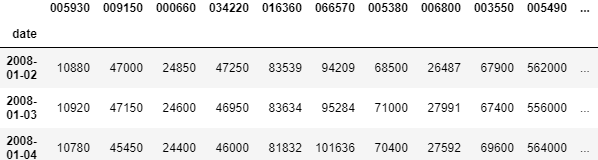
# rows와 columns 출력 테스트
print('\n', raw_data.iloc[:10, :5], '\n')
Output:
Exploration
plots을 통해 데이터를 explore해보도록 하겠습니다.
Input:
import matplotlib.pyplot as plt
for lab in indicators.keys():
indicator = raw_data[[x for x in raw_data.columns
if x.split("_")[-1] == lab]]
indicator.plot(title=lab)
plt.show()
Output:
US의 GDP 성장율이 클수록 인구의 증가가 빠르다는 것을 부분적으로 설명할 수 있을 것입니다. 이것은 우리의 모델에 의해 captured 되어야 합니다.
Transformation
우리는 우리 모델의 데이터를 사용하기 전에, 적절한 모델로 transform해줘야 합니다.
Input:
import numpy as np
# 절대 값 대신에 우리는 상대적인 변화율을 이용할 것입니다.
# Nan값 때문에 오류가 발생할 수 있습니다.
data = np.log(raw_data).diff().iloc[1:,:]
# NaN을 0으로 채움.
data.fillna(0, inplace=True)
# 각 Series에서 평균값을 뺌
data = data - data.mean()
# index의 데이터 타입을 변경
data.index = pd.to_datetime(data.index, format='%Y')
# target variable 데이터만 뽑아서 target 변수에 넣음.
target = data[[x for x in data.columns if x.split("_")[-1] == target_variable]]
Evaluation
모든 모델들은 같은 방법으로 평가됩니다. 데이터의 마지막 연도를 예측하기 위해 우리는 각 나라의 이전 년도 데이터를 이용하여 모델을 훈련합니다. 각 예측에서 우리는 실제 값과 예측된 값의 차이를 제곱하여 error를 계산합니다. 그리고 mean을 구한 뒤, 제곱근을 취함으로써 우리는 root mean squared error (RMSE)를 구할 수 있습니다.
ŷ𝒾 는 forecast 값, 𝘺𝒾 는 타겟 변수의 실제 값, 그리고 m은 우리가 예측할 년도의 개수입니다.
Baseline forecasts
우리는 먼저 simple baseline method 로 performance를 확인 해 본 뒤, subsequent methods와 비교해 볼 것입니다. baseline method는 간단하게 목표 변수의 이전 관측치와 동일한 변화율을 예측할 것입니다.
더 복잡한 방법은 naive baseline forecast보다 두드러지게 outperform하는 경우에만 사용하는 것이 좋습니다. the principle of Occam's Razor와 the KISS principle을 지키는 것이 좋습니다.
Input:
errors = target.iloc[-nyears:] - target.shift().iloc[-nyears:]
# Root mean squared error
rmse = errors.pow(2).sum().sum()/(nyears*ncountries)**.5
print('\n\t' + '-' * 18)
print("\t| Error: ", np.round(rmse, 4), '|')
print('\t' + '-' * 18 + '\n')
Output:
Multivariate time series
우리는 이제 multivariate time series regression의 performance를 조사해 볼 것입니다.
계량 경제학에서는 Vector Autoregression (VAR)이라고도 불립니다.
d는 독립 변수의 수, 𝜀는 lag의 수, εt 는 error term, βi,jβi,j 는 추정된 파라미터입니다.
시계열 분석에 대한 자세한 내용을 알기 위해서는 Brockwell과 Davis의 "Time Series: Theory and Methods"와 Hamilton의 "Time Series Analysis"를 추천합니다.
모델을 fit하기 위해서 우리는 statsmodels 패키지를 사용합니다. 여기서 VAR 구현은 최소 제곱을 사용하여 매개 변수를 추정합니다. 하나의 lag를 이용하여 model을 훈련시킵니다. 즉, 독립 변수의 가장 최근 이전 값에서 대상 변수를 regression하지만, lag의 수를 설정을 지원하는 automatic methods도 있습니다. the Akaike Information Criterion (AIC) 나 Bayesian Information Criterion (BIC) 등이 있습니다.
Input:
from statsmodels.tsa.api import VAR
# Sum of squared errors
sse = 0
for t in range(nyears):
# Create a VAR model
model = VAR(target.iloc[t:-nyears+t], freq='AS')
# Estimate the model parameters
results = model.fit(maxlags=1)
actual_values = target.values[-nyears+t+1]
forecasts = results.forecast(target.values[:-nyears+t], 1)
forecasts = forecasts[0,:ncountries]
sse += ((actual_values - forecasts)**2).sum()
# Root mean squared error
rmse = (sse / (nyears * ncountries))**.5
print('\n\t' + '-' * 18)
print("\t| Error: ", np.round(rmse, 4), '|')
print('\t' + '-' * 18 + '\n')
Output:
우리는 복잡한 VAR모델이 거시 경제 예측을 위해서 baseline model과 거의 동일하다는 것을 알 수 있습니다.
Gaussian process regression
우리는 이제 Gaussian process regression을 이용하여 GDP를 예측할 것입니다. 우리의 모델은 이전과 비슷합니다.
𝘺𝑡는 타겟 변수의 관측치입니다. 각 𝓍𝑡는 독립 변수의 관측된 벡터입니다. 𝑓(𝓍)는 regression 함수이고 noise term ε𝑡은 분산 α를 갖는 normal (Gaussian) distribution을 가지고 있습니다. 각 out-of-sample 예측에서 우리는 타겟 변수 y의 n년 간의 관측된 값을 column vector로 넣고 y로 나타낼 것입니다. 우리는 또한 각 관측치가 행렬에서 행을 차지하는 n년간 독립 변수의 관측치의 matrix를 X라고 할 것입니다. 여기서 각 관찰은 변수의 lagged values들을 포함할 것입니다.
회귀 함수 𝑓 (𝓍)가 임의의 매개 변수를 가진 선형 함수인 대신에, 함수는 이제 랜덤한 값을 가지므로 각 점 𝓍𝑡에서의 값은 정규 분포의 확률 변수이고 두 개의 확률 변수 𝑓(𝓍𝑡)와 𝑓(𝓍𝑠)는 소위 공분산 함수 (또는 커널) 𝑘(𝓍𝑡, 𝓍𝑠)에 의해 주어지며, 이것들은 지정되어야 합니다. 𝑓(𝓍) 함수는 '가우시안 프로세스'라 불립니다. error term이 정상적으로 분포되기 때문에 목표 값은 𝑡 = s이고 𝑘 (𝓍𝑡, 𝓍𝑠) 이면 𝑘 (𝓍𝑡, 𝓍𝑠) +𝑎 와 같은 공분산으로 정규 분포됩니다.
𝘺𝑡 와𝓍𝑡 에 대해 nn 개의 데이터 포인트를 사용하여 모델을 추정하고, 우리가 ŷ 𝑛+₁ 의 예측을 토대로 새로운 테스트 포인트 𝓍𝑛+₁을 가지고 있다고 가정합시다. 주어진 y, 𝑋 ,𝓍𝑛+₁ 에서 f(𝓍𝑛+₁) 의 조건부 분포는 또한 정규 분포를 가지며 ŷ𝑛+₁ 의 예측을 𝑓(𝓍𝑛+₁)의 조건부 기대 값으로 삼을 수 있습니다. 잘 알려진 공식인 multivariate Gaussian distribution은 아래와 같습니다.
K는 n X n 행렬 (행 t와 열 s에 대한 엔트리는 𝑘 (𝓍𝑠, 𝓍𝑡)로 주어지고, 𝐼는 항등 행렬이며, 𝐤는 𝑘(𝓍𝑡,𝓍𝑛+₁)에 의해 주어진 t를 갖는 길이 n의 열 벡터입니다.
classification에도 사용되는 Gaussian process methods를 더 읽기 위해서는, Rasmussen 과 Williams의 "Gaussian Processes in Machine Learning"을 보는 것을 추천합니다.
Gaussian process regression은 scikit-learn 패키지를 이용합니다. 각 예측 연도에 대해 과거 타겟 변수의 관측치들의 벡터 y와 독립 변수의 관측치들의 data matrix X를 생성합니다.
우리는 이것들을 GaussianProcessRegressor 클래스에 제공하여 모델을 estimate한 다음 다음 해에 대한 예측을 할 것입니다. 이전과 마찬가지로 RMSE를 사용하여 오류를 계산합니다.
우리는 아래와 같은 common Gaussian covariance function을 사용할 것입니다.
∥v∥ 는 vector vv의 길이이고 , σσ 는 매개변수입니다.
Input:
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
# 우리는 covariance function의 매개변수를 일반적인 covariance function의
# heuristic인 데이터 포인트의 median으로 사용합니다.
# The 'alpha' 인수는 잡음 분산이며, 우리가 covariance 매개변수와 동일하게 설정합니다.
gpr = GaussianProcessRegressor(kernel=RBF(0.1), alpha=0.1)
# 각 예측의 estimation/fitting을 위한 데이터 포인트의 수
ndata = target.shape[0] - nyears - lags
print(ndata)
# Sum of squared errors
sse = 0
for t in range(nyears):
# 타겟 변수의 관측치
y = np.zeros((ndata, ncountries))
# 독립 변수의 관측치
X = np.zeros((ndata, lags * ncountries * nindicators))
for i in range(ndata):
y[i] = target.iloc[t + i + 1]
X[i] = data.iloc[t + i + 2:t + i + 2 + lags].values.flatten()
gpr.fit(X, y)
x_test = np.expand_dims(data.iloc[t + 1:t + 1 + lags].values.flatten(), 0)
forecast = gpr.predict(x_test)
sse += ((target.iloc[t].values - forecast) ** 2).sum()
rmse = (sse / (nyears * ncountries)) ** .5
print('\n\t' + '-' * 18)
print("\t| Error: ", np.round(rmse, 4), '|')
print('\t' + '-' * 18 + '\n')
Output:
우리는 지금까지 얻은 결과를 정리해보면 Gaussian process regression을 사용하여 얻은 결과는 baseline과 linear regression models과 비교하여 약간의 성능 개선이 있다는 것을 확인할 수 있었습니다.